Utiliser Dead Letter dans RabbitMQ pour temporiser les messages en cas d'erreur
RabbitMQ est rapide, si le nombre de consumer est correctement dimensionné les messages sont dépilés quasi instantanément ce qui peut poser des soucis dans certains cas. Je ne compte plus le nombre de fois où j'ai reçu l'exception Doctrine NoResultException pendant le traitement d'un consumer, car le message avait été consommé immédiatement et manque de chance à ce moment là la réplication de base avait du retard.
La simplicité c'est le mal.
Dans ce cas, le plus simple à faire est de NACK le message, il revient donc se mettre dans la queue et attendre qu'un consumer le consomme de nouveau. Le problème c'est que ce message sera le prochain dépilé et risque de provoquer la même erreur si le retard de réplication de la bdd n'est pas rattrapé. J'ai bien dit au début que RabbitMQ est rapide. Avec cette technique de l'autruche, on va tomber dans une pseudo boucle infinie : consommation du message > erreur > NACK qui va durer le temps de rattraper le retard de la réplication. Si la consommation du message dure 0.5 seconde, alors un retard d'une minute va couter 120 consommations du même message pour rien. En plus de charger le serveur, cela va également apporter une charge inutile au serveur de base.
Une autre approche serait de ACK le message pour qu'il ne revienne pas se placer dans la queue puis soit de l'envoyer par mail avec l'erreur ou de publier dans une queue d'erreur pour le traiter manuellement plus tard. J'ai choisis cette solution au début de mon utilisation de RabbitMQ, c'est simple et facile à mettre en oeuvre.
Admettons que j'ai une queue nommée "synchro_user" toute simple bindé à un exchange "synchro" avec la routing_key "user"
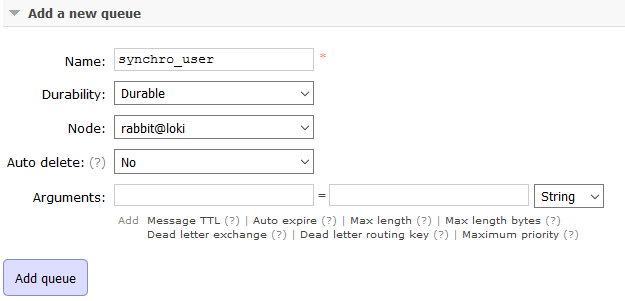
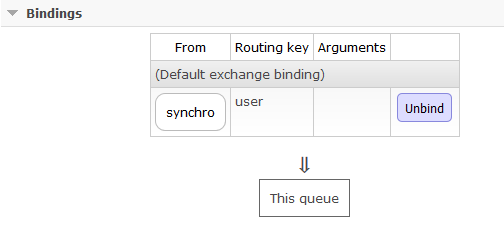
On peut également déclarer la configuration avec l'outil rabbitmqadmin en ligne de commande. Il peut être télécharger depuis le plugin d'administration s'il est installé depuis l'url http://<domain>:15672/cli/rabbitmqadmin
$ ./rabbitmqadmin --vhost=/ declare queue \ > name=synchro_user durable=true $ ./rabbitmqadmin --vhost=/ declare binding \ > source=synchro destination=synchro_user \ > routing_key=user
Je crée une seconde queue "synchro_user_error" que je vais bindé à un exchange "synchro_error" avec la routing_key "user_error".
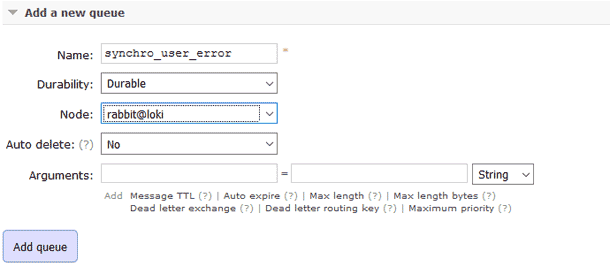
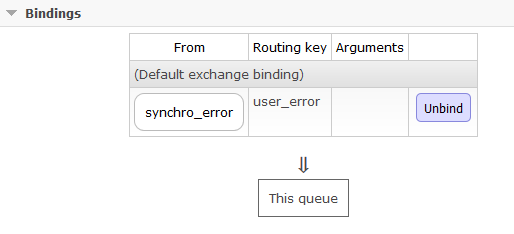
$ ./rabbitmqadmin --vhost=/ declare queue \ > name=synchro_user_error durable=true $ ./rabbitmqadmin --vhost=/ declare binding \ > source=synchro_error destination=synchro_user_error \ > routing_key=user_error
Ainsi je me retrouve avec la queue "synchro_user" qui est consommée et quand une erreur survient je publie mon message dans l'exchange "synchro_error" pour qu'il arrive dans la queue "synchro_user_error".

Mais avec le temps, j'ai ajouté de plus en plus de queue dans RabbitMQ ce qui a mécaniquement augmenté le nombre de message en erreur à devoir traiter à la main ce qui est consommateur de temps. Et puis quand on arrive le matin, que le serveur a crashé et qu'on retrouve plus de 4000 messages en queue d'erreur, euh.......
Have you met DLX & DLK ?
RabbitMQ propose beaucoup d'options et mises bout à bout on peut automatiser une temporisation de message. Je m'explique.
Je garde mon principe, si j'ai une erreur lors de la consommation de la queue "synchro_user", je renvoie le message dans la queue "synchro_user_error". Par contre je vais modifier la définition de cette queue. En réalité je vais la supprimer et la re-créer car les choses sont immutables dans RabbitMQ.
Je commence par ajouter un ttl sur ma queue d'erreur. Je considère qu'au bout de 5 minutes les messages dans cette queue doivent être jetés. A cela j'ajoute l'option dead letter exchange (DLX) et dead letter routing key (DLK). Ces options me permettent de publier le message ailleurs une fois le ttl atteint. Mon DLX est donc "synchro" et mon DLK "user", attention à ne pas oublié de refaire la binding entre la queue "synchro_user_error" et l'exchange "synchro_error".
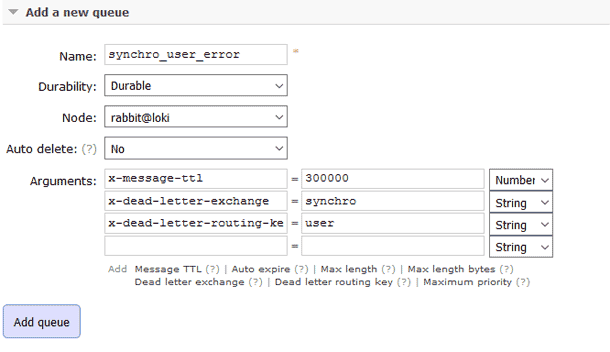
$ ./rabbitmqadmin --vhost=/ declare queue \ > name=synchro_user_error durable=true \ > arguments='{"x-message-ttl": 300000, "x-dead-letter-exchange": "synchro", "x-dead-letter-routing-key": "user"}' $ ./rabbitmqadmin --vhost=/ declare binding \ > source=synchro destination=synchro_user_error \ > routing_key=user_error
De ce fait, l'apparence de ma queue change dans le tableau.

Et voilà! J'ai donc maintenant un système qui me permet de résoudre automatiquement mes problèmes de retard de réplication. Si j'ai une erreur durant la consommation d'un message, je l'envoie dans la queue d'erreur. RabbitMQ se charge tout seul de republier ce message dans la queue d'origine à la fin du tll de 5 min que j'ai spécifié.
Ce mécanisme est également quasi indispensable si votre consumer fait appel à une API externe pour retenter plus tard si elle ne répond pas.
Ajouter un commentaire